Однажды разработчик, искавший просветления в области создания встроенных систем взобрался на Гору опыта, чтобы проконсультироваться с сидящим на вершине Оракулом. Оракул знал, что программисты встроенных систем встречаются с трудностями, понимание которых недоступно простым смертным. Им нужно заставить работать без сбоев в течение нескольких месяцев сложный прибор, соблюдать строгие рамки по распределению памяти и процессорного времени и решать загадки взаимодействия в режиме реального времени.
Молодые программисты, полные радостных школьных воспоминаний о библиотеках шаблонов и пошаговых отладчиках, не могли постичь всю глубину мудрости Оракула. Для понимания ценности знания Оракула требовались многие годы опыта работы со встроенными системами. Каждый день программисты приходили искать ответы на такие вопросы, как «Как мне написать более быстрый код?» и «Какой компилятор лучше?» С такими зелёными вопрошающими Оракул был немногословен: «Не спрашивайте столь неважные вопросы. Только достойный сможет понять смысл моих ответов».
Наш разработчик спросил Оракула: «О, Оракул, как мне увидеть и понять, что делает моя система?»
И ответил Оракул: «Твой вопрос указывает на твою зрелость, молодой странник, так как понимание является ключом, открывающим дверь к улучшению. Лучше зажечь свечку, чем проклинать тьму».
И Оракул поделился Десятью секретами, которые были результатами долгий лет, проведённых им на вершине Горы опыта:
- Знай свои инструменты
- Проблемы с памятью лучше находить заранее
- Сначала пойми, потом оптимизируй
- Не клади иголки в стог сена
- Воспроизведи и изолируй проблему
- Знай, где ты уже был
- Убедись, что тесты полны (хорошо покрывают код)
- Делай всё качественно – это экономит время
- Посмотри, пойми, а затем сделай так, чтобы оно работало
- Используй мышление новичка
- Знай свои инструменты
«Когда у тебя есть только молоток, все проблемы выглядят как гвозди».
Хороший механик пользуется многими инструментами, поскольку починить машину только одним молотком нельзя. Так и программист должен умело обращаться со своими инструментами. У каждого из них своё место, каждый обладает эффектом Гейзенберга, у каждого есть свои сильные стороны.
Инструменты позволяют многое понять в том, как работает система. С помощью специально созданных для встроенных систем инструментов можно увидеть, как это происходит вживую – что делает твоя программа, какие ресурсы она использует, и как она взаимодействует с внешним миром. Способность разобраться в существе вопроса сильно увеличивается, поскольку благодаря этим инструментам можно быстро найти ошибки, спорные моменты и неэффективные участки кода, обнаружение которых с помощью других средств, как правило, заняло бы несколько дней.
Для того чтобы быть эффективными, инструменты должны обладать не только мощными средствами визуализации, они также должны быть пригодны к использованию в системе. Системы реального времени гораздо более чувствительны к вмешательству извне, нежели настольные системы. Не будет ли этот профайлер тормозить систему? Пользовательскому интерфейсу хуже от этого не станет. Однако если это приведёт к тому, что сетевой интерфейс начнёт терять пакеты, то такой профайлер вряд ли стоит применять в вашем встроенном приложении.
Кроме того, инструменты надо использовать. Применение контрольно-измерительной аппаратуры или изменение кода требуют времени и сил. Даже просто перекомпиляция с новыми флагами может быть преградой, особенно для больших групповых проектов. Большинство программистов не берутся за инструмент. Они сначала несколько раз попытаются изменить и перекомпилировать код. Хоть каждый шаг и кажется несущественным («Я просто попробую вставить printf»), эти попытки приводят к существенному снижению производительности разработчиков. Страх и инертность мешают многим программистам использовать инструменты, которые имеются в их распоряжении.
Отладчик исходного кода (Source-level debugger) позволяет пошагово выполнять твой код, останавливать его и затем исследовать содержимое памяти и значения программных переменных. Это первый фундаментальный инструмент, применяемый для решения проблемы.
Простая команда printf (или её эквивалент в вашем языке программирования) является, наверное, самым гибким и примитивным инструментом. Вывод значений переменной позволяет определить то, как работает программа. К сожалению, команду printf неудобно использовать (требуются изменение кода и перекомпиляция), а также это влияет на выполнение приложения, сильно замедляя его. Кроме того, данная команда может создавать потоки данных, которые затрудняют понимание настоящей проблемы.
Внутрисхемные эмуляторы (ICE) и JTAG-отладчики позволяют тщательно контролировать работающий чип. На ранних стадиях процесса разработки какой-либо специальной платы внутрисхемные эмуляторы жизненно необходимы. Просто нет никакого другого средства для полного контроля процессора, когда вы не доверяете «железу». Отладку платы можно начинать, как только она выходит из перезагрузки. Это позволяет видеть всё, что происходит за первые критические микросекунды. Вы можете отлаживать код в ROM. Вмешательство в работу системы минимально и его можно, как правило, игнорировать. Однако, как только операционная система начинает работать, аппаратных средств иногда начинает не хватать. Аппаратные эмуляторы – это не производительные процессоры. Они не очень хорошо справляются с отладкой многих процессов. По своей гибкости они даже близко не стоят рядом с полным набором программных инструментов.
Мониторы данных (Data monitors) позволяют, не останавливая систему, узнать, что происходит с переменными. Мониторы данных могут в процессе выполнения приложения собирать данные из многих переменных, сохранять историю изменения и графически представлять её в «живом» режиме.
Мониторы операционной системы (Operating system monitors) отображают события, такие как переключения задач, семафоры и прерывания. Эти мониторы позволяют визуализировать связи между событиями операционной системы и их синхронизацию. Они легко позволяют решать такие проблемы, как инверсия семафора приоритета, взаимоблокировки и задержки прерываний.
Профайлеры следят за тем, на что процессор тратит свои такты. Профайлер может рассказать, где находится "узкое" место, насколько занят процессор, а также намекнуть, где стоит заняться оптимизацией. Поскольку профайлеры показывают, где был и что делал процессор, с помощью них можно понять, что на самом деле выполняется, а это ценный «глазок» в систему.
Тестеры памяти (Memory testers) ищут проблемы в использовании памяти. Они могут находить утечки, фрагментацию и повреждения. Тестеры памяти – это первая линия атаки для решения непредсказуемых и нерегулярных проблем.
Трассирующие отладчики (Execution tracers) показывают, какие операции были выполнены, кто и когда их вызвал, и какими были параметры. Эти инструменты необходимы для слежения за логическим потоком программы. Они отлично справляются с задачей поиска редких явлений в огромном потоке событий.
Тестеры полноты (Coverage testers) показывают, какой код выполняется. Они помогают убедиться в том, что твои тестовые операции обрабатывают все возможные ветви кода, что существенным образом увеличивает качество тестирования. Они также помогают в устранении отмёрших участков кода, которые больше не используются.
Проблемы с памятью лучше находить заранее
Проблемы с памятью очень коварны. Их можно разделить на три главных типа: утечки, фрагментацию и повреждение. Лучший способ бороться с ними – это находить их как можно быстрее.
Утечки памяти – это наиболее известная «скрытая» проблема программирования. Утечка памяти происходит тогда, когда программа выделяет всё больше и больше памяти с течением времени. В конце концов, у системы заканчивается память и она «падает». Эта проблема, как правило, бывает скрытой, так как участок кода, вызвавший сбой, когда у системы кончилась память, зачастую к причине утечки никак не относится.
Даже самые прилежные программисты иногда допускают утечки. Самая очевидная причина – это ошибка программирования – код выделяет память и не освобождает её. Любой, кто хотя бы раз искал утечку в сложном коде, знает, что найти её, зачастую, почти невозможно. Гораздо более хитрые (и частые) утечки происходят, когда библиотека или системный вызов выделяет память и не освобождает её. Иногда это бывает ошибкой в библиотеке, но чаще всего это непонимание при прочтении документации по API.
К примеру, программисты из компании Nortel занимались переносом большого сетевого UNIX-приложения на VxWorks. В заключительном испытании на принудительный отказ они обнаружили утечку. Память медленно утекала по 18 байт каждые несколько секунд, что, в конце концов, вызывало сбой. Откуда и почему утекала память, было совершенно непонятно. Пристальное изучение кода в течение нескольких недель не дало никакого результата.
Десять минут работы с инструментом обнаружения утечек, и загадка была решена. Оказалось, что простой вызов сетевой функции inet_ntoa в VxWorks выделял память, а в UNIX – нет. Эта функция была хорошо документирована, просто две её реализации немного различались. Изменение одной строки устранило проблему.
Программистам компании Nortel повезло. При системном тестировании редко обнаруживаются утечки памяти. Медленно текущая система может работать днями или месяцами перед тем, как проявится проблема. Даже расширенные испытания могут не обнаружить утечки, которая происходит только в условиях интенсивного сетевого трафика при реальном использовании.
На самом деле, большинство утечек никогда не обнаруживаются, даже в уже работающих системах. Они просто проявляются в «случайных» сбоях, которые списываются на нестабильность оборудования, нагрузки, броски напряжения, ошибки оператора или на что-нибудь другое, что происходило в это время. В лучшем случае, надёжность будет не критична, и пользователи научатся периодически перезагружаться. В худшем случае утечки могут уничтожить уверенность покупателя, сделать продукт бесполезным или опасным и привести к тому, что весь проект потерпит неудачу.
Поскольку утечки наносят такой большой вред, для борьбы с ними были разработано большое число способов. Существуют средства поиска блоков, на которые нет ссылок, и блоков растущей выделенной памяти, специальные языки, надёжно контролирующие сбор мусора, библиотеки, следящие за выделением памяти, и даже спецификации, требующие от программистов вообще отказаться от выделения памяти во время выполнения. Каждый способ имеет свои за и против, но любой из них более эффективен, чем незнание. Обидно, что многие системы страдают от утечек в то время, когда существуют эффективные меры противодействия. Ответственные программисты тестируют свои программы на утечки.
Фрагментация памяти ставит ещё более хитрые задачи. Так как память выделяется и освобождается, большинство распределителей режут большие блоки памяти на меньшие блоки размером в одну переменную. Выделенные блоки распределяются в памяти, в результате чего образуется набор маленьких свободных блоков, для нарезания новых кусочков. Этот процесс называется фрагментацией. В сильно фрагментированных системах можно просто не найти свободный блок памяти на 64 Кб, даже если свободно несколько мегабайт. Даже системы со страничной организацией памяти, которые не страдают от фрагментации так сильно, могут замедляться и терять память с течением времени из-за неэффективного использования блоков.
Небольшая фрагментация – это правда жизни в большинстве систем с динамически выделяемой памяти. Это не проблема, если система подходит под шаблон, в котором хранится достаточное количество свободной памяти; фрагментация не будет угрожать долгосрочной работоспособности программы. Однако если фрагментация накапливается с течением времени, система в конце концов «упадёт».
Как часто твоя система выделяет и освобождает память? Накапливается ли фрагментация? Как нужно писать код для уменьшения фрагментации? В большинстве систем единственным решением является использование инструмента, который показывает карту памяти твоей работающей системы. Понять, что вызывает фрагментацию и затем переработать код (как правило, сделать несложное изменение) для её ограничения.
Любой код, написанный на языке, который поддерживает указатели, может повредить память. Существует множество путей получения таких повреждений: запись за границы массива, запись в освобождённую память, ошибки в арифметике указателей, повисшие указатели, запись за границы стека и другие ошибки. На практике оказывается, что большинство повреждений памяти происходит из-за какого-либо сохранённого состояния, которое не отчищается при освобождении памяти. Классическим примером является блок памяти, который выделяется, предоставляется библиотеке или операционной системе в качестве буфера, а затем освобождается и забывается. Тогда повреждение ждёт и может произойти в произвольное время в будущем. Повреждённые системы совершенно непредсказуемы. Подобные ошибки, мягко говоря, найти очень не легко.
Кстати, не нужно вводить себя в заблуждение, думая, что системы с защищённой памятью предотвращают появление повреждений. Защита памяти всего лишь останавливает другие процессы при попытке перекрёстного повреждения твоего процесса. Защищённые процессы легко могут повреждать свою собственную память. На самом деле, большинство повреждений памяти происходит именно таким образом. Большинство ошибок повреждения происходят при записи в область «около» другой памяти (за конец массива, через старый указатель в уже освобождённую память, и т.д.). Существует высокая вероятность, что плохие области памяти всё ещё находятся в записываемом адресном пространстве процесса, что приведёт к повреждению. Единственными способами борьбы с повреждениями памяти являются поддержка различных средств на уровне языка программирования и тестирование.
Сначала пойми, потом оптимизируй
Реальное время – это скорее надёжность, нежели скорость. Это значит, что эффективный код необходим для многих встроенных систем. Умение заставить свой код «летать» является фундаментальным навыком, который должен освоить каждый программист, работающий со встроенными системами.
Первым делом следует обкромсать самую жирную свинью. Скажем, если вам дадут приложение с модулем на 20 тысяч строк и функцией на 20 строк, с чего вы начнёте оптимизацию?
Ага! Это вопрос с подвохом. Функция с 20 строками может вызываться тысячи раз или вообще зациклиться в одной строчке. Суть в том, что заставить код работать быстрее – простая часть задачи. Сложная часть заключается в определении самого кода, который нужно заставить работать быстро.
Это можно проиллюстрировать с помощью примера. Компания Loral занималась созданием роботизированного контроллера для исследования возможных пространственных операций. Это была сложная система, состоящая из множества приборов, сложных уравнений, сетевых интерфейсов и интерфейсов оператора.
В один прекрасный день система перестала работать. Процессор был загружен на 100%. Управляющий цикл, который обычно выполнялся 300 раз в секунду, едва выдавал 40. Все как один утверждали, что «ничего не изменялось».
С помощью простого профайлера проблема была локализована в подпрограмме транспонирования матрицы, которая съедала 80% процессорного времени. Кажущееся тривиальным (и забытое) изменение уравнения контроллера привело к тому, что операция транспонирования выполнялась каждый цикл. Подпрограмма транспонирования выделяла и освобождала временную память, а поскольку процесс выделения памяти происходит медленно, падала производительность всей системы.
Оптимизация каждой строчки кода, замена всего оборудования, использование других компиляторов и метод пристального вглядывания никогда бы не привели к устранению этой проблемы. Этот случай типичен, поэтому, когда дело доходит до оптимизации производительности, как правило, требуется всего небольшое изменение в правильном месте. Никакие программистские трюки на планете не сработают, если ты не знаешь, куда смотреть.
Проблемы производительности могут даже выдавать себя за другие проблемы. Если процессор не отвечает на внешние события, переполняются очереди, теряются пакеты или оборудование не обслуживается, ваше приложение может «упасть». И вы можете так и не заподозрить в этом проблемы производительности.
К счастью, профилирование производительности делается просто и быстро. Оно также откроет вам глаза на вещи, о которых вы даже не подозревали, и позволит вам достичь лучшего общего понимания. Сколько раз копируется структура данных? Сколько раз мы обращаемся к диску? Включает ли этот вызов передачу данных по сети? Правильно мы назначили приоритеты задач? Не забыли ли мы выключить отладочный код?
Профилирование систем реального времени представляет собой уникальную задачу. Вам нужно использовать профайлер, в то время как свободной мощности процессора очень мало. Но большинство профайлеров сами требуют много процессорного времени. Замедлять систему и всё ещё получать точную картину происходящего не получится. Мораль заключается в том, что необходимо чётко понимать эффект Гейзенберга своего профайлера – любое измерение меняет систему.
Мы закончим этот раздел ещё одной историей. Компания ArrayComm создавала базовую станцию беспроводной пакетной передачи данных и пользовательский терминал. Продукт был почти готов к сдаче, но никак не мог пройти тесты на большие нагрузки. Оптимизация не помогала. Хронометраж критических участков кода не помогал. Интенсивный контроль со стороны менеджеров также не помогал. Перепробовав все варианты, разработчики уже подумывали над тем, чтобы переделать систему на использование более быстрого процессора. Такое решение стоило бы нескольких месяцев работы и миллионов долларов.
В отчаянии, они выполнили профилирование системы. За считанные минуты они обнаружили, что более трети циклов уходила на функцию, закопанной в стеке протокола третьей компании. Отключение опциональной возможности проверки атрибутов, которая была включена для отладки, привело к увеличению пропускной способности почти в два раза. Продукт был сдан две недели спустя.
Знай, как твой процессор выполняет твой код. Это единственный путь к эффективности.
Не клади иголки в стог сена
Поиск иголок в стоге сена является хорошей метафорой для описания большинства процессов отладки. Так как вы ищите иголки? Начните с того, что не роняйте их в стог. Всем разработчикам известно это тянущее ощущение, что они срезают угол и создают баг на будущее. Остановись и послушай свой внутренний голос! Следуй руководящим принципам хорошего программирования, проверяй свои предположения, обдумывай свои алгоритмы. Если ничего другого не остаются, помести в комментариях метку, что этот код под подозрением, чтобы это место было легко найти.
Существует большое количество источников, в которых есть полезные советы, как разрабатывать встроенные системы. Статья Дейва Стюарда (Dave Stewart) "Двадцать пять наиболее распространённых ошибок при разработке программного обеспечения реального времени" ("Twenty-Five Most Common Mistakes with Real-Time Software Development") будет хорошим началом. Скачать её можно по адресу www.embedded-zone.com/esc/mistake.pdf.
Следующий шаг заключается в поиске иголок до того, как они укололи тебя. К примеру, трассировка – это хорошо, когда проблема неясна. Но в полной силе она может проявиться как предупредительная мера. Регулярный поиск вызовов операционной системы, которые возвращают ошибки, может обнаружить многие проблемы на ранних стадиях разработки и тестирования. Думай об этом как о регулярном поиске большого числа иголок в стоге своей системы.
Как это сделать? Используй свой инструмент трассировки для поиска ошибок, возвращаемых функциями операционной системы или других API. Изучи все неожиданные моменты. Все ли вызовы malloc работают? Не заканчиваются ли вызовы неожиданно по тайм-ауту? Также проверь значения параметров. Не обнуляются ли указатели, передаваемые в ключевые функции? Не вызывается ли что-нибудь гораздо чаще или реже, чем предполагалось? Трассировка даёт возможность «почувствовать» код. Если проводить её регулярно, до того, как иголки превратились в проблемы, то стог будет в безопасности.
Воспроизведи и изолируй проблему
Если все-таки иголка обнаружилась, раздели свой стог сена на части. Первым шагом процесса отладки сложного приложения, создаваемого группой разработчиков, является, как правило, изолирование проблемы. Вся хитрость заключается в том, как это сделать эффективно.
Если проблема проявляется нерегулярно, то важный первый шаг – это достоверно повторить её: воссоздать и ликвидировать. Найди любую последовательность действий, которая точно приводит к появлению проблемы, и половина задачи решена. При тестировании всё записывай. Следи за всем, что меняется. Организованный и тщательный подход очень важен для того, чтобы изолировать проблему.
Как только обнаружен способ точного воспроизведения проблемы, можно начинать делить стог на части. Выключи все фичи, помести под #ifdef целые блоки, выдели из системы самый маленький кусочек, в котором проблема всё ещё проявляется.
Если проблема серьёзная, то открывай ящик с инструментами. Если ты подозреваешь, что происходит повреждение переменной, настрой ICE на остановку системы при её изменении. Проследи за ней с помощью монитора данных. Используй трассировщик для получения подробной истории вызываемых функций, в том числе и переданных параметров. Проверь, не повреждена ли память. Проверь, не переполняется ли буфер.
Давайте проиллюстрируем это с помощью примера. В процессе разработки, программисты компании Candera заметили странную проблему, в результате которой показания системных часов прыгали вперёд на огромное значение. С помощью ICE они нашли проблему – функции операционной системы передавался неправильный параметр. Однако этой информации было недостаточно для исправления ошибки. Винить функцию операционной системы нельзя, ведь кто-то передал ей неправильный параметр. И естественно, это привело к появлению проблемы типа иголки в стоге сена – строчек кода много, и данная функция операционной системы вызывалась очень много раз. В данном случае трассировщик использовался для записи всех вызовов функции ОС, что позволило быстро найти ошибочный код.
Знай, где ты уже был
Гензель и Гретель умно поступили, решив оставить след из хлебных крошек. Обратно отслеживаемая маркировка является прекрасным способом обеспечить понимание будущих проблем. Единственной настоящей ошибкой Гензеля и Гретеля (кроме той, что они допустили, поверив ведьме) было использование недостаточно стойких средств записи своего продвижения. Не повторяйте их ошибку.
Когда ты добился от приложения или модуля значительной степени работоспособности, создай контрольную точку. Позже, когда он перестанет работать, даже если «ничего не изменялось», у тебя будет основа для проверки своих предположений.
Как это сделать? Используй систему управления кодом. Когда код работает, запиши промаркированную версию, чтобы командой diff с ней можно было сравнивать будущие состояния. Проверяй эффективность системы с помощью соответствующих программ и документируй степень производительности различных модулей. Отслеживай поведение операционной системы, ключевых переменных и использование памяти. Регистрируй эти параметры при работающем коде. Эти карты из прошлого здорово тебе помогут, когда ты потеряешься в будущем. Одна только эта привычка сэкономит тебе половину времени отладки системы. В следующий раз, когда твоё приложение внезапно начнёт использовать на 50% больше процессорного времени или памяти, будет гораздо проще изолировать и определить проблему, имея перед глазами характеристики предыдущей версии.
Убедись, что тесты полны
Насколько исчерпывающие твои тесты и как ты это определяешь? Оценка полноты тестирования может ответить на оба этих вопроса, оно точно показывает какой код выполнялся и проверяет законченность твоего набора тестов.
Умудрённые опытом тестеры полноты скажут тебе, что большинстве наборов тестов проверяют лишь от 20 до 40% всего кода. Оставшийся код может содержать баги, которые ждут своей возможности проявиться.
Оценка полноты тестирования должна быть частью каждого качественного процесса проверки. Сколько раз ваш код был пересмотрен и переписан за много лет и релизов? Изменяется ли ваш набор тестов соответственно? Или тесты проверяют только возможности, которые существовали ещё в версии 1.0? Оценка полноты тестирования может хорошо занять вашу группу тестирования, но основательный отчёт о полноте тестов позволит менеджерам вашего продукта нормально спать по ночам.
Различные типы тестирования полноты начинаются с простой проверки того, что был совершён вход в каждую функцию, и кончаются проверкой того, что все возможные пути пройти по всем возможным ветвям, были протестированы. Большинство инструментов поддерживают различные уровни тестирования.
Требуемый уровень тестирования определяется приложением. Ты пишешь код, который управляет встроенной в сидения видеосистемой самолёта или его закрылками? Для видеосистемы проверка того, что большинство функций программы выполняется, может быть достаточно. В случае закрылок ты должен знать, что при принятии решающим параметром значения ложь, код обработки ошибок выполняется не в самый первый раз.
Оценка полноты тестирования также выявит отмёрший код. Большинства программ содержит 20% или даже больше кода, который никогда не выполняется. Убрались ли какие-либо фичи из последнего релиза? Заботит ли тебя суммарный объём кода? Если да, то взгляни на свой отмёрший код.
Даже если ты уверен, что твои тесты полны и что у тебя в программе нет отмёршего кода, определение полноты тестирования может выявить скрытые баги. Посмотри на следующий фрагмент кода:
if (i >= 0 && (almostAlwaysZero == 0 || (last = i)))
В этом коде содержится ошибка. Если almostAlwaysZero когда-либо примет ненулевое значение, то переменная "last" примет значение i, а это вряд ли то, чего требуется. Проверка полноты условий покажет, что эта последняя часть решения никогда не выполняется. Кстати, проверки полноты функций, утверждений и решений не обнаружат этой ошибки, они просто убедятся в том, что обе ветви утверждения if выполняются.
Делай всё качественно – это экономит время
Исследования показывают, что 74% всей статистики выдуманы. А если более серьёзно, то наш опыт указывает на то, что более 80% времени разработки тратится на:
- Отладку своего собственного кода
- Отладку при интеграции своего кода с чужим кодом
- Отладку всей системы
Более того, исправление ошибки в конце разработки стоит в 10 – 200 раз дороже, чем в начале. А цена небольшой ошибки, пробравшейся в уже установленную систему, может быть просто астрономической. Даже если баг не имеет значительного влияния на производительность, он может существенно ухудшать воспринимаемое качество продукта. Спросите об этом разработчиков микрокода по операциям с плавающей точкой оригинальных процессоров Pentium. Несколько лет назад Intel поставила несколько миллионов чипов с небольшим браком. Хоть практически все приложения работали без ошибок, это была катастрофа для службы работы с клиентами, так как им впервые пришлось отзывать чип, причём компания понесла убытки на 475 миллионов долларов.
Нельзя достичь высокого качества, откладывая тестирование на конец процесса разработки. Качественное тестирование уменьшает время, требуемое для понимания проблемы, и сильно ускоряет разработку. Заведи себе привычку проводить тестирование и поиск ошибок каждый день. Тогда ты будешь писать код быстрее и лучше.
Посмотри, пойми, а затем сделай так, чтобы оно работало
По определению, системы реального времени взаимодействуют с динамическим миром. К сожалению, традиционные отладчики не могут позволить понять динамику поведения системы. Отладчики работают только со статическими значениями остановленных программ. На вопросы типа
- Насколько шумит мой датчик?
- Насколько быстро растёт очередь?
- Когда закрылся клапан?
Инструменты, которые останавливают выполнение ответить просто не в состоянии. Эти вопросы напрямую связаны с динамическим характером систем реального мира. Ответы на них может дать только динамический инструмент, анализирующий программу в процессе выполнения.
Думай о своей встроенной программе как об автомобиле. Отладчики исходного кода подобны гаражу механика. Ты можешь привезти свою машину для обслуживания, механики остановят двигатель, поставят машину на домкрат, и посмотрят, как выглядит каждая деталь. Это очень ценный сервис, он позволяет решить много проблем. Однако статическая проверка не может дать ответ на такой вопрос как, например, «Почему дрожит руль?» Хоть в гараже и могут снять всё рулевую систему и найти сносившуюся деталь, там никогда не обнаружат множество других причин.
Если причина заключается в том, что «Вы ездите по бездорожью», в гараже этого не скажут. Другие вопросы, такие как, «С какой скоростью я еду?» и «На сколько сантиметров я не доехал до грузовика?» не найдут ответа в мастерской механика. Остановка машины изменяет природу системы.
Некоторые вопросы возникают, только когда машина движется, и найти на них ответ можно, только обладая возможностью понаблюдать за её поведением на дороге.
Это также применимо к большинству встроенных систем. Многие важные системы реального времени совсем не могут быть остановлены. К примеру, остановка сетевой системы для того, чтобы понять, как долго заполняется рабочая очередь, может вызвать мгновенное переполнение. Размещение контрольной точки в программе управления рукой робота может быть опасным. С течением времени происходят другие операции. К примеру, установка совмещения и последовательного шагового мультиплицирования на пластину выполняет по порядку большое число шагов. Для оценки качества её работы может быть необходимо просмотреть поведение системы на протяжении всей последовательности действий.
Мониторы реального времени предоставляют информацию о динамике системы. Они не останавливают систему. Они собирают данные в живом режиме и отображают их в реальном времени. Их существуют несколько типов для решения различных проблем. Наиболее распространённы мониторы операционной системы, мониторы данных и профайлеры.
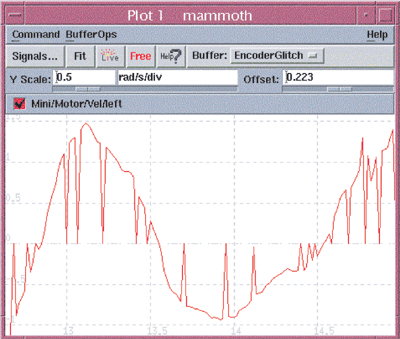
Рисунок 1: Данные с датчика на двигателе, показывающие произвольные нулевые показания
Это можно пояснить с помощью примера. На рисунке 1 приведены данные, которые были измерены с помощью датчика, расположенного на двигателе. Двигатель был частью системы, которая сильно вибрировала. Не было ясно, была ли вибрация обусловлена плохим устройством системы управления, неисправным механическим компонентом или проблема скрывалась в каком-то из многочисленных датчиков и двигателей системы.
Использование монитора данных мгновенно сузило проблему и указало на датчик скорости на одном из двигателей. Более того, это позволило установить источник ошибки – случайное неверное показание нулевого значения.
Данный датчик был оптическим кодером, который не имел прямого вывода значений скорости. Вместо этого, его выходной сигнал положения использовался для расчёта скорости двигателя с помощью высокочастотного счётчика, который считал импульсы с кодера. Программное обеспечение считывало значения этого счётчика и вычисляло сигнал скорости, приведённый на рисунке 1.
Монитор мгновенно показал, что сигнал положения от оптического кодера не содержал ошибок. Таким образом, проблема вряд ли заключалась в самом кодере. После мониторинга всех других переменных, использовавшихся в промежуточных расчётах, от аппаратных регистров до конечного сигнала скорости, можно было заключить, что драйверное программное обеспечение тоже был не виновато. Однако аппаратные регистры иногда содержали неверные отсчёты. Таким образом, проблема должна была быть в электронике кодера.
Это как раз тот тип проблем, которые почти невозможно найти с помощью традиционного отладчика. Потребовалось бы большое количество контрольных точек точно в нужных местах (и немного удачи) для обнаружения этого случайного нулевого отсчёта. Но использование монитора данных позволило за считанные минуты определить симптомы и выявить источник проблемы. Без онлайн-монитора потребовалось бы (и, скорее всего, так бы оно и случилось) несколько дней на обнаружение неисправной электроники.
Этот пример рассказывает о поиске неизвестной проблемы. Зачастую, очень важно просто понимать, что происходит на немного более глубоком уровне – хороший шофёр иногда выглядывает из окна, чтобы убедиться, что он всё ещё на дороге, перед тем, как колёса начнут трястись. Регулярно проводите мониторинг своей системы просто для того, чтобы понимать её лучше. Итог: не будь удовлетворён тем, что твоё приложение работает, пойми, как именно оно работает.
Используй мышление новичка
«В мышлении новичка есть много возможностей, в мышлении мастера – немного.» Шанриу Сузуки
Отладка – это в основном процесс изучения своего приложения. Марафонские сессии отладки, которые исследуют каждую деталь программы, являются зачастую единственным способом собрать достаточно информации и для нахождения и исправления ошибки.
Но есть и альтернатива. В течение сосредоточенного марафона твоё сознание закрыто для возможностей. Предположения становятся неоспоримыми фактами. Ты начинаешь знать вещи, которые просто неверны. Ты не рассматриваешь возможности, безосновательно отвергая их.
«Мышление новичка» – это дзен-буддистская концепция освобождения своего сознания для того, чтобы оно было открыто для новых решений. Сила мышления новичка не должна быть недооценена. Пара свежих глаз может творить чудеса. Даже совсем пустое сознание, как, например, у менеджера, может помочь.
Поэтому когда ты совсем застрял, когда ты посмотрел на проблему со всех доступных тебе точек зрения, когда все инструменты из твоего ящика тебя подвели, возьми таймаут и подумай. Сходи покатайся на велосипеде. Днём отдохни, а вечером возвращайся и посмотри на всё в новом ракурсе. Объясни проблему другу, менеджеру, собаке или даже стенке. Критика твоих предположений часто являются катализатором, который помогает преодолеть преграду.
Достигни мастерства
Отладка – это, без сомнений, искусство. Однако, как и в других видах искусства достичь успеха можно лишь сочетая талант, опыт и совершенное владение необходимыми инструментами.
Секреты отладки не являются загадкой. Знай свои инструменты. Если можешь, избегай частых опасных ошибок, а затем проверяй, удалось ли тебе это. Не забывай о профилактике. Сохраняй данные для сравнения прошлого с настоящим, даже если «ничего не изменилось». Сохраняй ясность взора и разума. И принимай ответственность за мастерство. Чтобы сдать систему, тебе надо сделать:
- Протестировать систему на утечку и повреждение памяти
- Поискать «узкие» места
- Собрать переменные ключевые последовательности
- Обеспечить достаточный запас производительности процессора
- Провести оценку полноты тестирования
- Отследить использование системных ресурсов
- Записать последовательности выполнения (семафоры, взаимодействия процессов) основных операций
- Проверить на возвращение ошибок различные API
Самая главная вещь, которой можно научиться у Оракула – это научиться сочетать стратегии для лучшего понимания своей системы в процессе разработки. Сложно найти разработчика, который думает, что Оракул попросту тратил время, используя инструменты, проводя качественные тесты или пытаясь понять, что же система делает. А обратное происходит каждый день. Пойми это, и Оракул убережёт тебя от беды.
Лори Фралей (Lori Fraleigh) работает директором группы ScopeTools компании Real-Time Innovations, где отвечает за средства визуализации и анализа для VxWorks и Linux. У Лори богатый опыт по созданию и разработке инструментов отладки встроенных систем с целью увеличения их производительности и надёжности. Она получила степень магистра электронного машиностроения в Стэнфорде и бакалавра в Пурде. С ней можно связаться по адресу: [email protected].
Стен Шнейдер (Stan Schneider) работает исполнительным директором Real-Time Innovations, которая была основана в 1991 году. Он специализируется на программных системах и архитектурах реального времени. Он создал много инструментов, включая монитор данных StethoScope, профайлер ProfileScope и оригинальную методику обнаружения утечек и повреждений памяти, использующуюся в программе MemScope. Он возглавлял лабораторию Аэрокосмической робототехники Стэнфорда и обладает большим опытом работы консультантом по техническим вопросам и вопросам управления в системах обработки сигналов и компьютерных системах реального времени во многих отраслях промышленности. Стен получил докторскую степень по электротехнике и вычислительной технике в Стэндфордском университете и бакалавра по прикладной математике. С ним можно связаться по адресу [email protected].
gale
Embedded.com